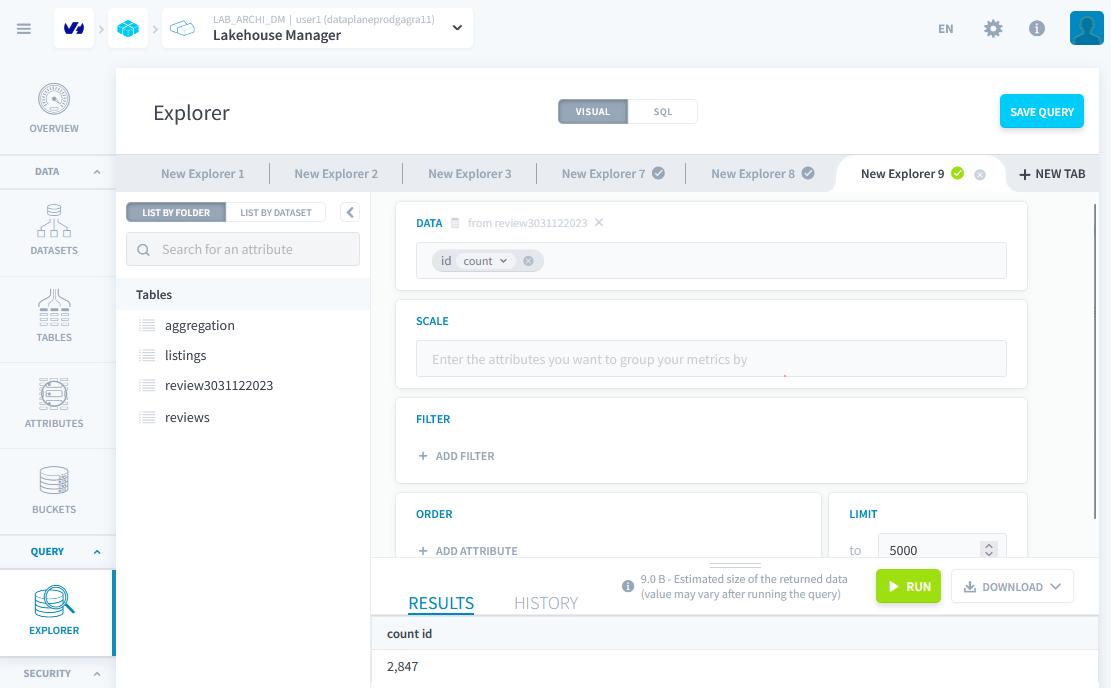
Cas d'utilisation AirBNB
Si vous n'avez pas de compte dataplatform, connectez vous à https://eu.dataplatform.ovh.net/ avec votre email et votre mot de passe
Configuration de la Source de Données
Datacatalog
L'objectif est d'obtenir deux fichiers csv à partir du point de terminaison s3 : reviews.csv et listings.csv. Allez dans la section Datacatalog et cliquez sur créer une source.
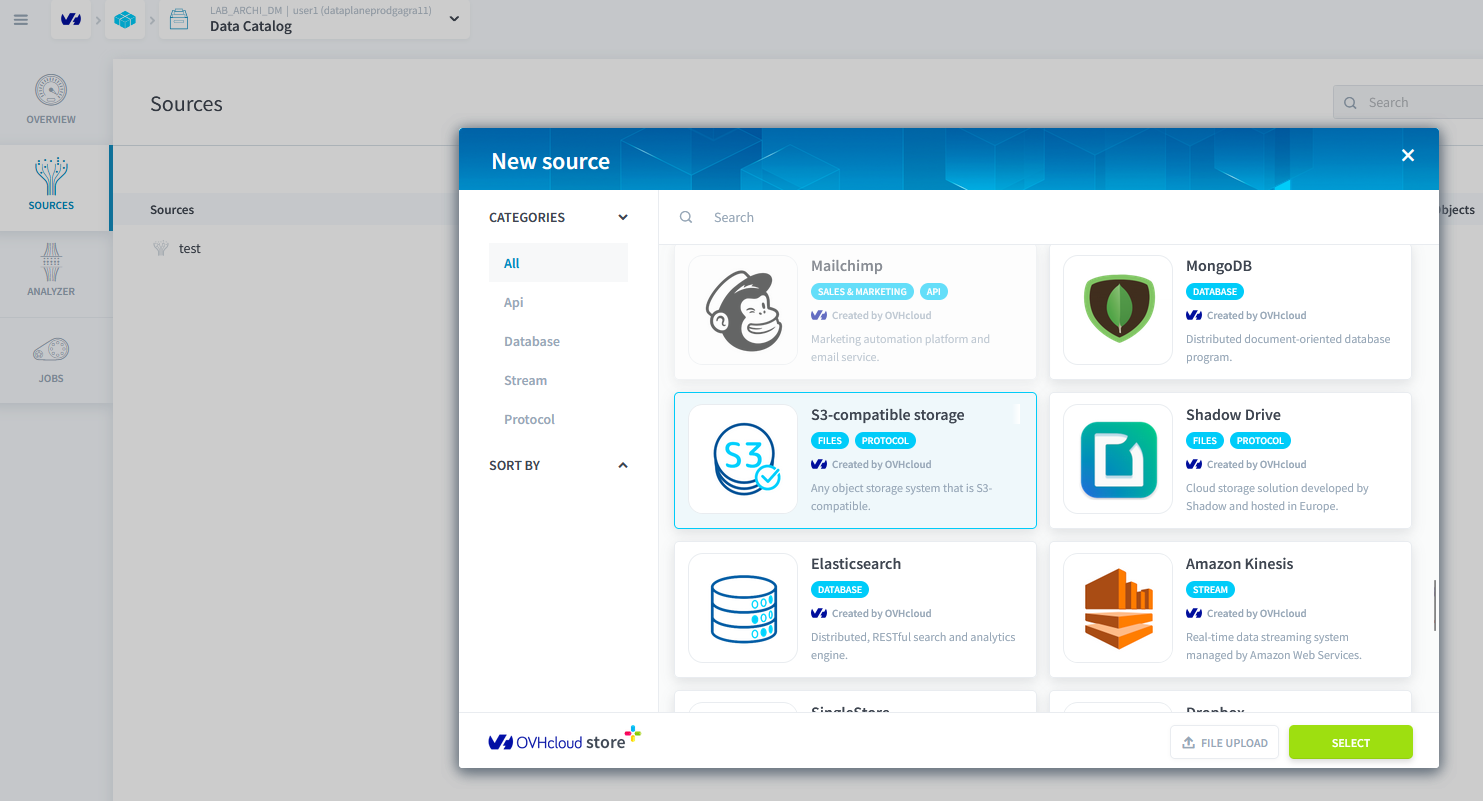
Étape 2 : Créer une Nouvelle Source de Stockage Compatible S3
Renseignez comme suit les informations pour créer une nouvelle source de stockage S3.
| Champ | Valeur |
|---|---|
| Access key | f15278c3829a4a03b1c4ed0ee779410c |
| Secret key | d4cfeb306fe44cd6b8cf78d8f9932fe1 |
| Endpoint | s3.gra.io.cloud.ovh.net |
| Bucket | rbnbfortechlab |
| Region | gra |
Étape 3 : Analyser les Données avec l'Analyseur
Allez dans la partie Analyser et lancez l'analyse sur les deux fichiers.
Voir l'impact des blueprints.
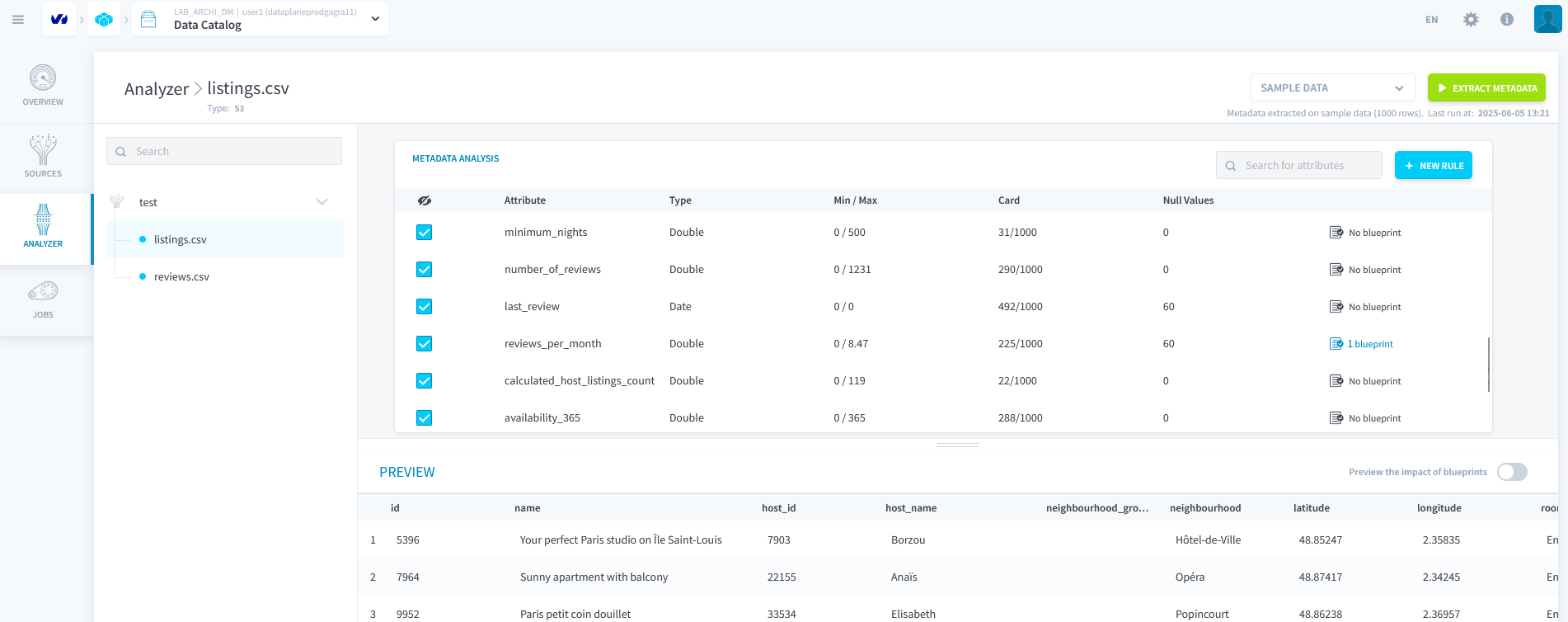
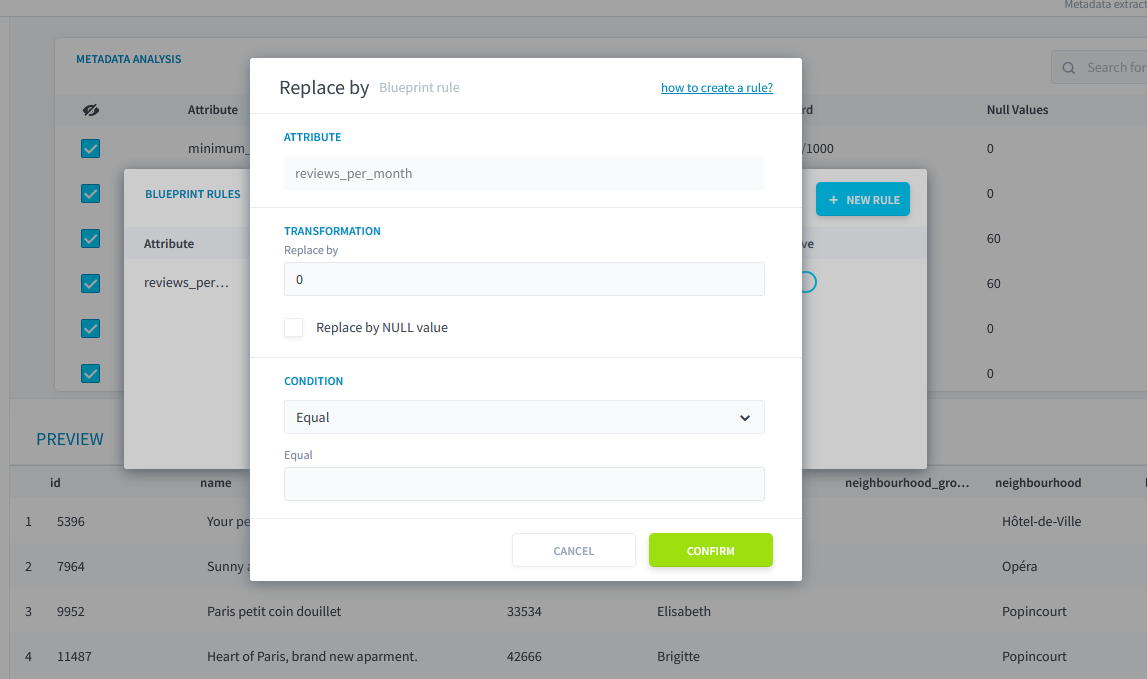
- Éditer l'attribut
review_per_monthdu blueprint et remplacer la règlereplace bypar la valeur0lorsque le champ est vide.
Configuration du Lakehouse Manager
Étape 1 : Créer des Tables à Partir des Sources de Données
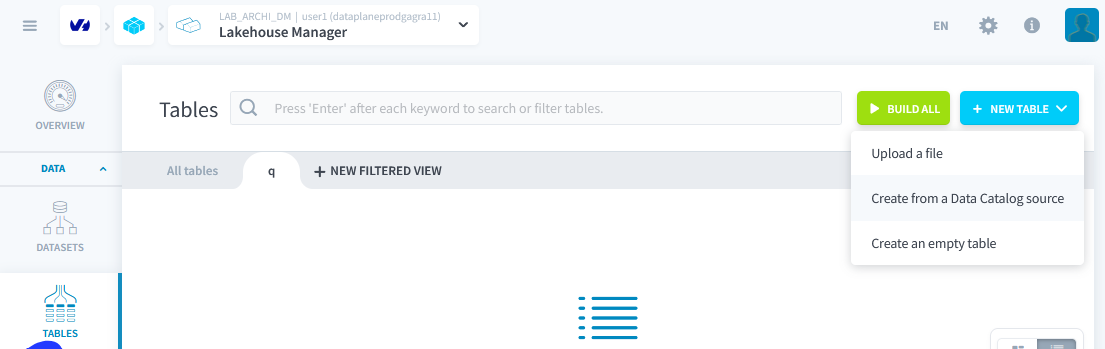
Créer 2 tables à partir des 2 sources de données précédentes : listings et reviews
Étape 2 : Créer des Tables de Travail
Créer une troisième table vide, avec 9 attributs, nommée aggregation
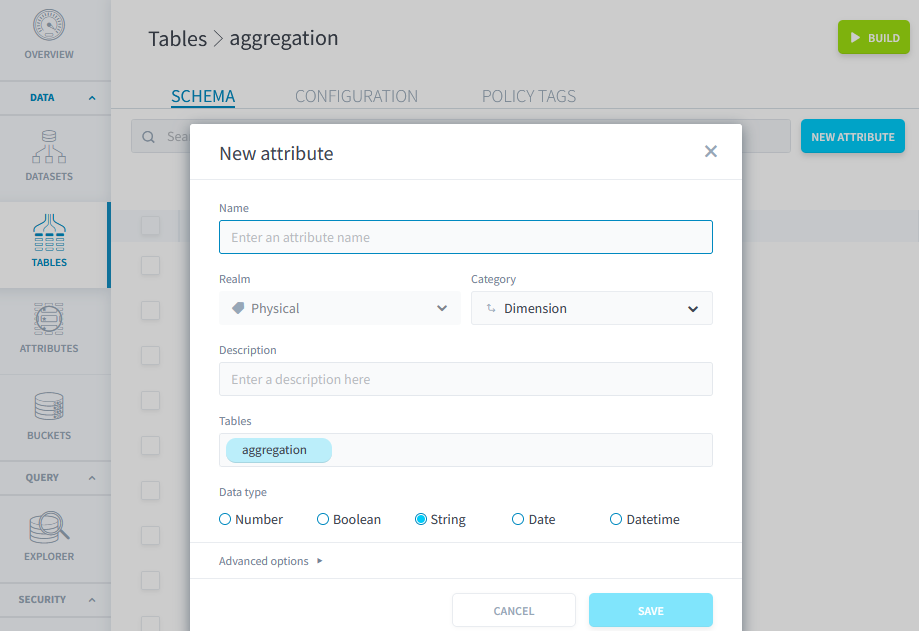
| Attribut | Type | Category |
|---|---|---|
| id | Double | Measure |
| latitude | String | Measure |
| longitude | String | Measure |
| room_type | String | Measure |
| price | Double | Measure |
| date | Date | Dimension |
| comment | String | Measure |
| emotion | String | Measure |
| avantage | String | Measure |
Vous pouvez maintenant construire la table. (Build en haut à Droite)
Dupliquer cette table et la nommer review3031122023
Reconstruire toutes les tables.
Création d'Actions et de Flux de Travail : Data Processing Engine
Vous avez déjà 2 actions de chargement prédéfinies : elles ont été créées lors de la création des tables à partir des sources de données.
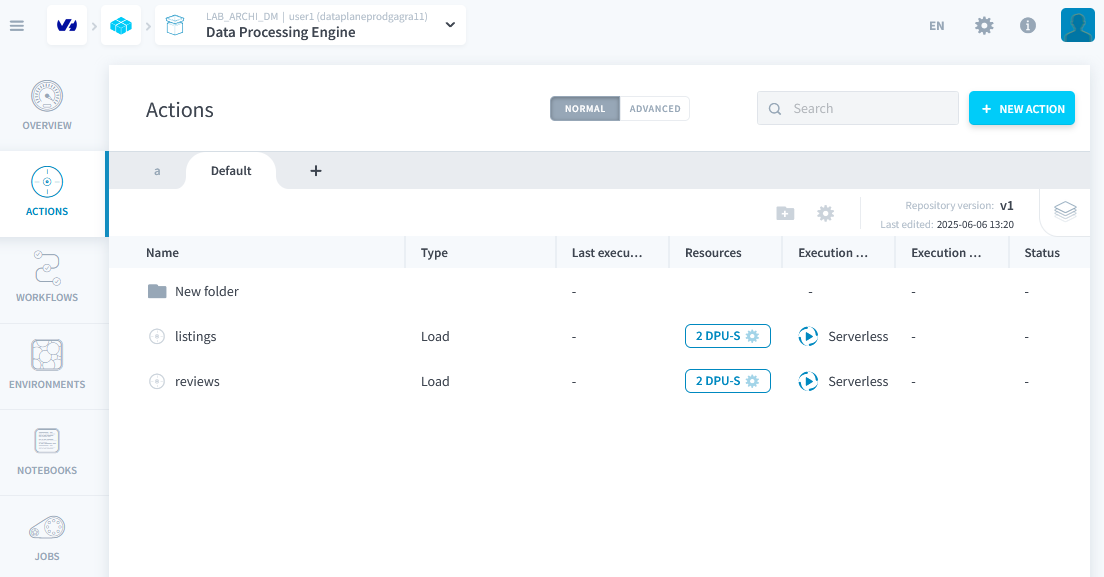
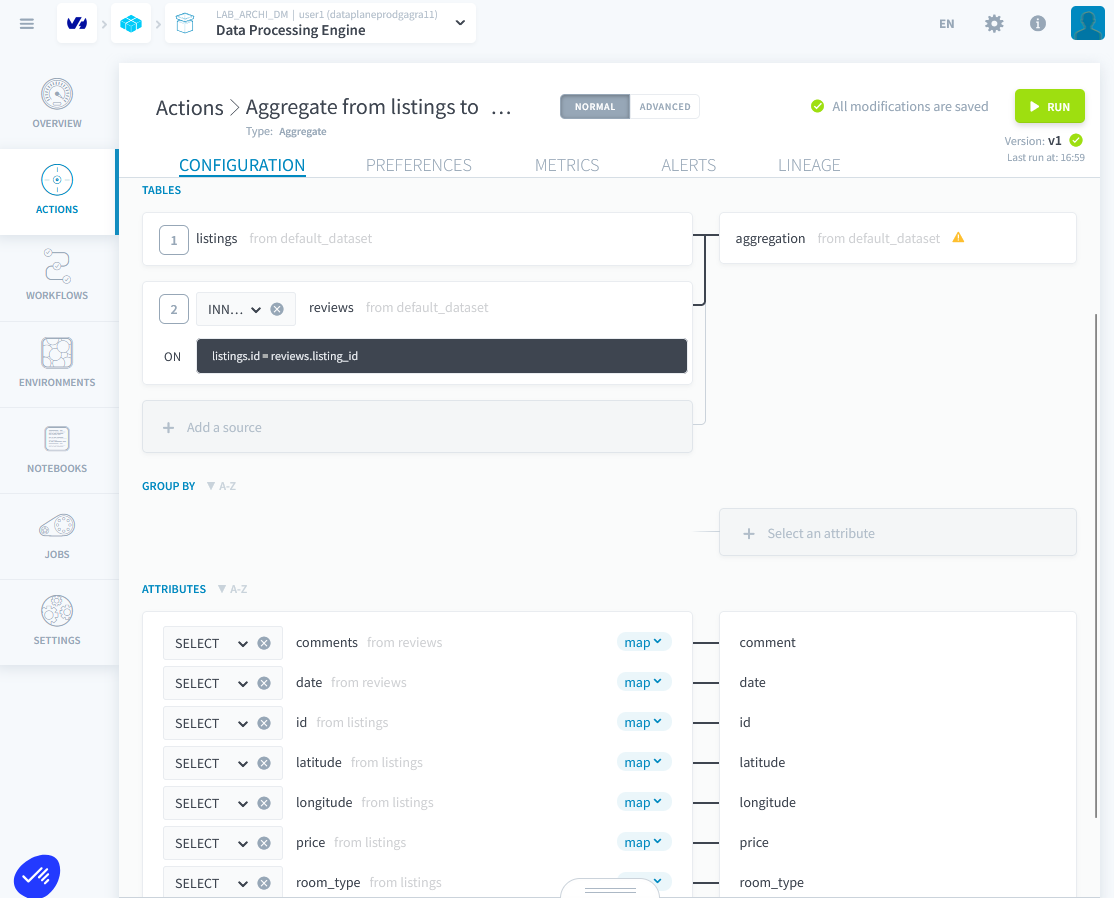
Étape 1 : Créer une Action d'Agrégation
- Créer une action d'agrégation et joindre sur id et listing_id, mettre l'agrégation dans la table d'agrégation.
listings.id = reviews.listing_id- Mapper les champs corrects et supprimer de l'agrégation l'émotion et l'avantage. Exécuter l'action.
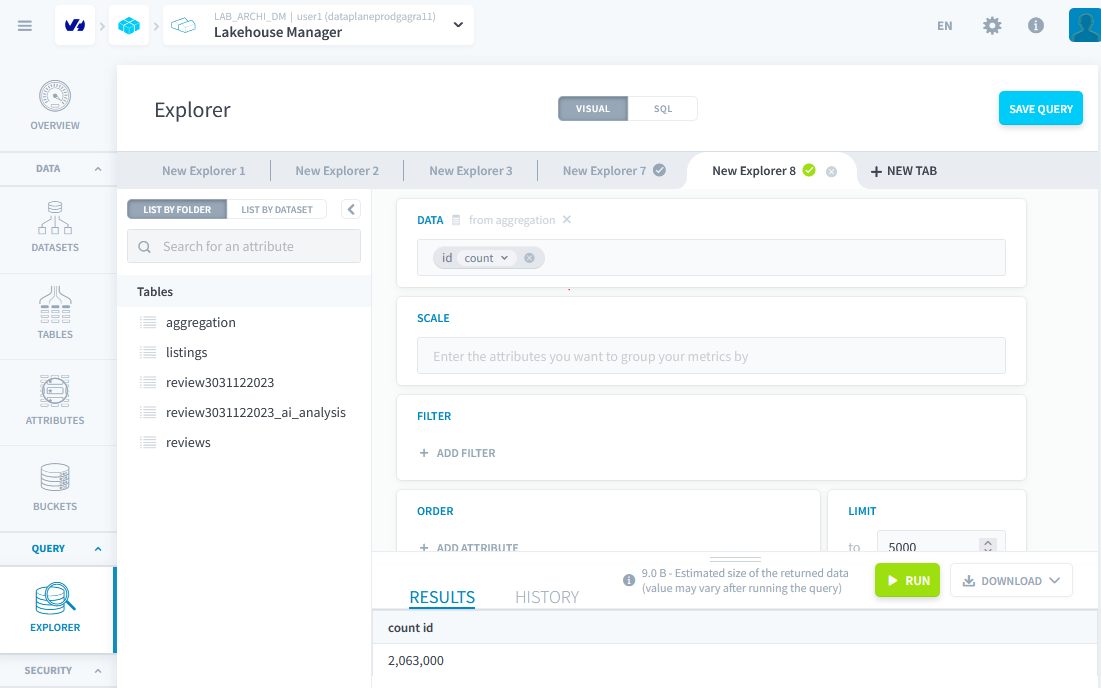
Après l'exécution correcte de l'action, vous pouvez vérifier dans Lakehouse manager => explorer que vos données sont là.
Étape 2 : Action Customisée
Maintenant, nous voulons uniquement les commentaires du 30 et 31 décembre 2023 afin de pouvoir plus tard lancer une analyse sentimentale via AI endpoint.
- Construire une action personnalisée en python avec pandas et mettre tous les commentaires de ces deux dates dans la table review3031122023.
Lien code à trou
https://rbnbfortechlab.s3.gra.io.cloud.ovh.net/workonlytwodays.py.
Lien de la solution
https://rbnbfortechlab.s3.gra.io.cloud.ovh.net/onlytwodays.py.
Exécuter l'action.
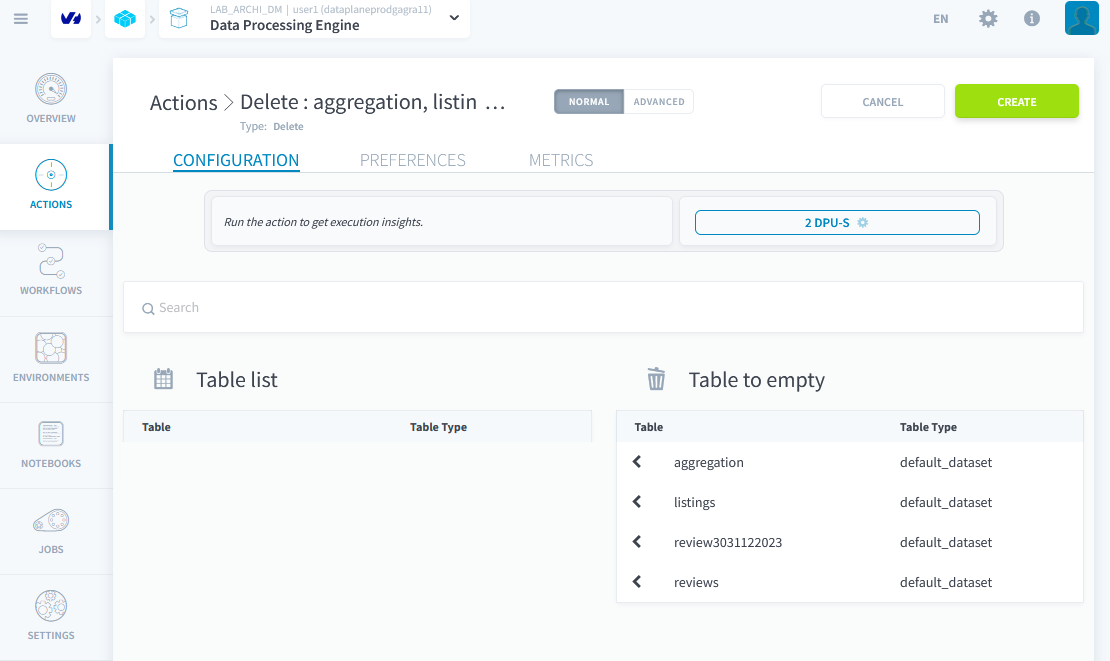
Création d'une Action de Suppression
Créer une action de suppression qui va vider toutes les tables.
Création d'un Workflow
Nous avons besoin de 4 étapes :
- Vider toutes les tables
- Charger les données brutes
- Agréger les deux premières tables
- Exécuter l'action personnalisée
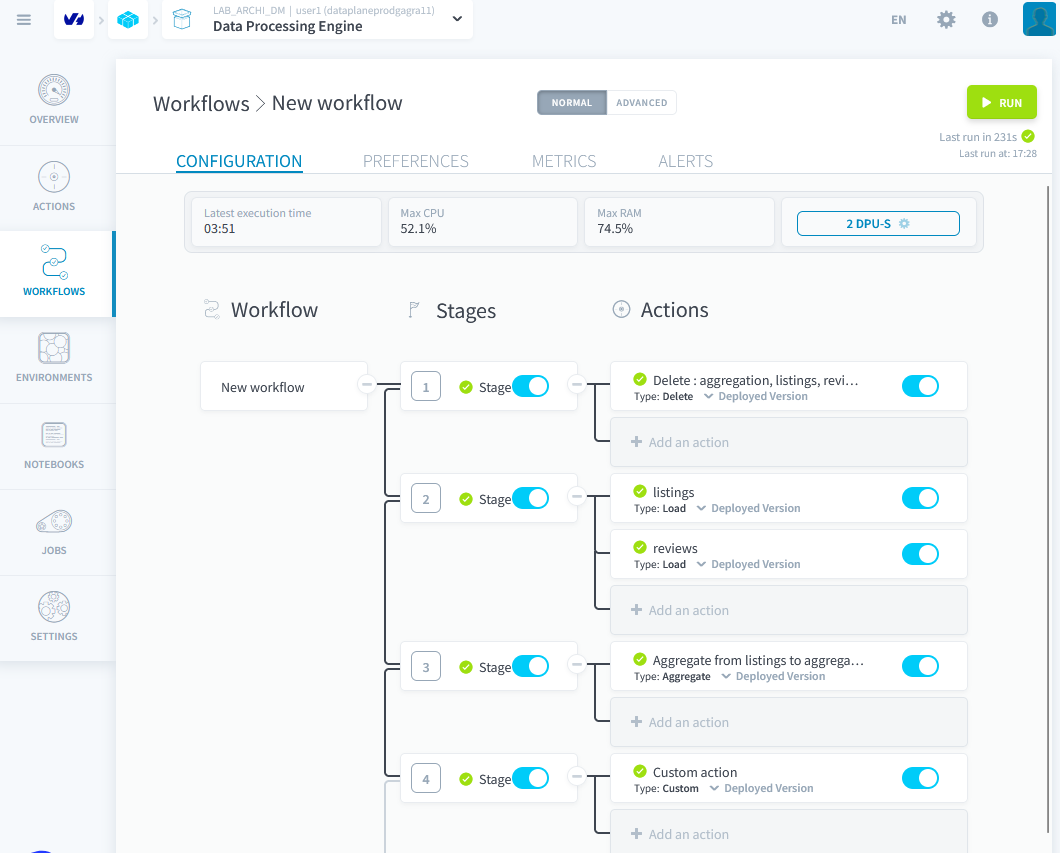
Vérifier que le Workflow fonctionne correctement en l'executant. Puis dans explorer verifiez que vous avez bien 2847 lignes dans la table